Data Classification Software
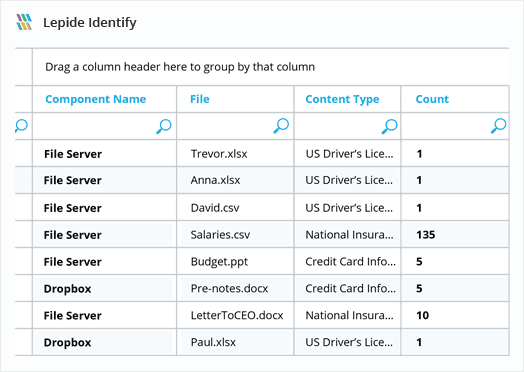
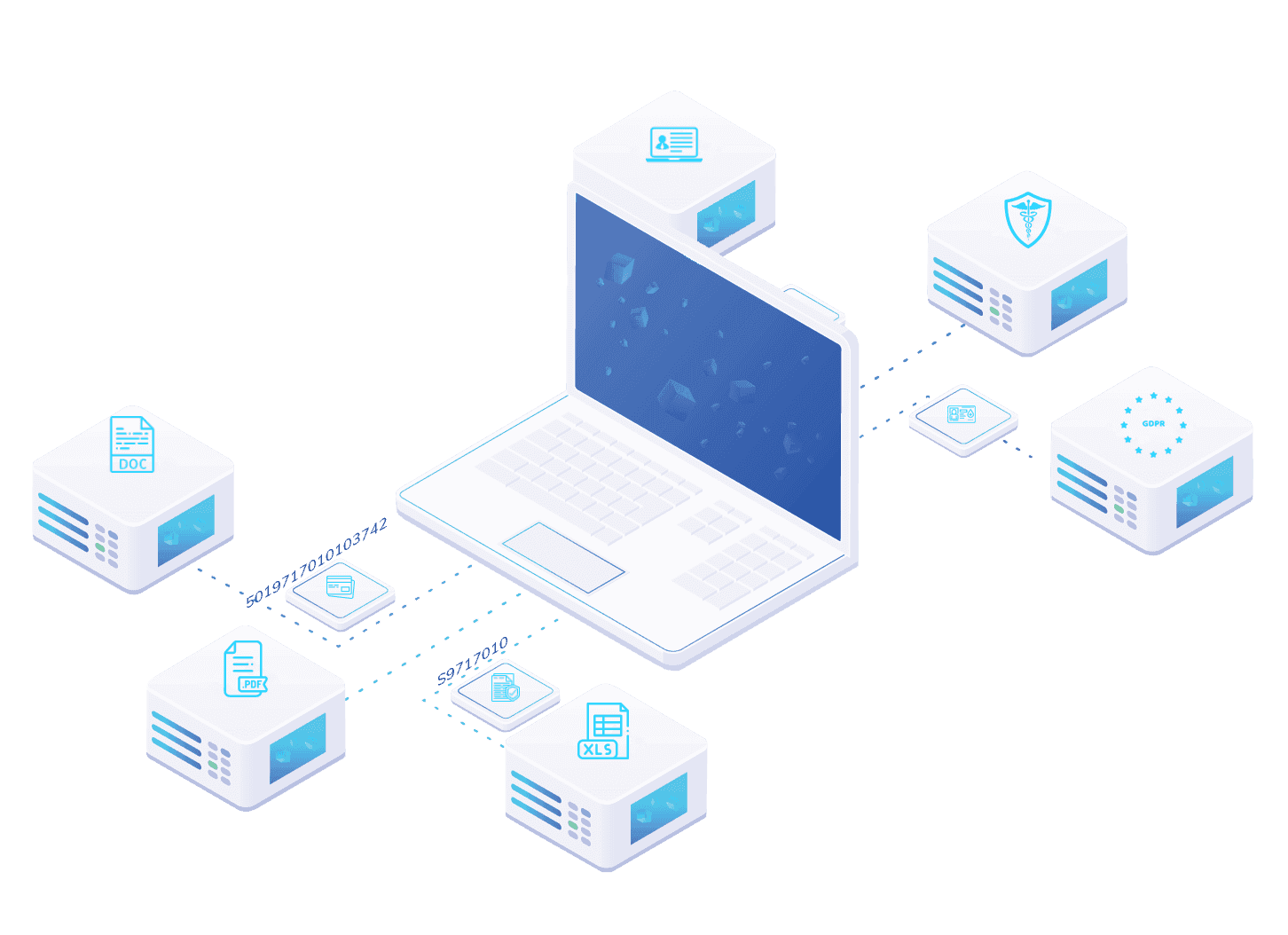
Get greater visibility over the content of your files with Lepide Data Classification Software. It automatically scans and classifies data related to PII, PHI, PCI, IP, and other regulations.
Fill in the rest of the form to
download the 20-day free trial
download the 20-day free trial













 Sensitive data discovery.
Sensitive data discovery.
 Persistent classification.
Persistent classification.
 Security with context.
Security with context.
 Automate Threat Response
Automate Threat Response
 Reduce False Positives
Reduce False Positives
 Govern Access More Effectively
Govern Access More Effectively
 Spot Risky User Behavior
Spot Risky User Behavior