


Last Updated on July 17, 2026 by Satyendra
For years, analysts like Gartner (along with enterprise security vendors) have pushed various versions of data-centric security models as the answer to risk reduction.
Data security posture management, data access governance, data loss prevention…what do they all have in common? They are all data centric.

But data doesn’t get breached on its own.
The vast majority of breaches that impact sensitive unstructured data are driven by identities and permissions. In most enterprises, these identities live in Active Directory or Entra ID. Microsoft themselves admit this, stating that “80% of incidents observed by Microsoft involved Active Directory” in their Digital Defense Report.
The current data-centric approach ignores this reality.
This creates a fundamental gap that we call the Identity-Data Disconnect.
In this blog, I’ll explain in more detail why data-centric security fails, why identity and data must be addressed together through the lens of permissions, and how to bridge the Identity-Data Disconnect with a practical framework.
What is the Identity-Data Disconnect?

The Identity-Data Disconnect, in simple terms, is the gap between who has access (identity) and what they can access (data). Most security vendors focus on one or the other, leaving organizations unable to see and control real risk across the full threat surface.
Identity and data have historically been treated as separate problems, requiring separate isolated solutions. Identity teams focus on managing users, groups, and authentication. Data security teams focus on discovering, classifying, and protecting sensitive data. Each facet builds visibility within its own domain but rarely is that visibility connected in a way that reveals real risk.
This disconnect is reinforced by the tools that teams use. Identity and access management (IAM) tools are great at revealing who exists and how access is granted, but they rarely extend that visibility into what data is actually exposed. Conversely, data-centric tools (DSPM, DLP, data access governance, etc.) start with the data itself, often without fully understanding the identity structures and permission models that govern access to it.
As a result, organizations end up with two incomplete views of risk, with neither being sufficient on its own.
The findings from Lepide’s State of Identity & Data Security 2026 research illustrate why identity and data security cannot be treated as separate disciplines. The assessment found that 79% of organizations had users with excessive permissions and 90% had enabled inactive Active Directory accounts, highlighting how identity governance gaps can directly contribute to data exposure.
This is the Identity-Data Disconnect – and it’s the reason why data-centric security fails.
Why Data-Centric Security Fails?
As vendors and analysts double down on data-centric models, the Identity-Data Disconnect is widening. New emerging categories and frameworks all seem to follow the same path (discover and classify, improve posture, monitor data usage) and fall victim to the same omission (Active Directory / Entra ID).
By focusing on data so heavily, without seeing it through the lens of Active Directory, the industry perpetuates and reinforces a fragmented view of risk.

Data-centric approaches to security always seem to emphasise that exposure and breaches are a data problem, when in reality it’s an access problem. Open shares, excessive access, and unmonitored permission changes are not issues that find their origins in the data itself – they start with Active Directory.
Until those layers are understood and connected to the data they govern, any view of risk will be incomplete. Imagine locking all your valuables in a safe without understanding who knows the code.
This is why data-centric security, on its own, fails.
How Do You Bridge the Identity-Data Disconnect?
Bridging the Identity-Data Disconnect involves combining identity and data security and seeing data risk through the lens of permissions. What this means in practical terms is that you need to:
- Start by understanding your identity threat surface.
- Link identities to the data that they can access.
- Understand what sensitive data you have.
- Observe how access is being used in practice (in relation to this sensitive data).
- Take action to reduce risk continuously.
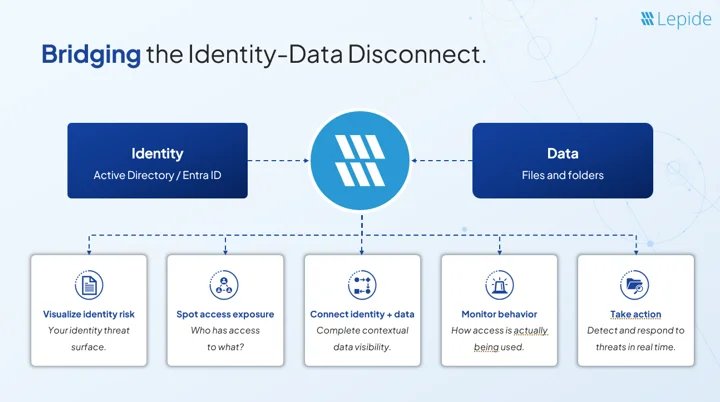
Individually, these steps are not new. But, when combined, they create a complete and connected view of risk that spans across identity, permissions, data, and behavior.
That is the foundation of what we’re calling the Identity-Data Framework.
The Identity-Data Framework
Below are the five steps you need to bridge the Identity-Data Disconnect. This framework can be implemented through Lepide:
Step 1. Understand your identity risk surface
In this step, the goal is to understand what your identity risk surface looks like, including things like:
- Users with admin access.
- Visibility into how access is granted.
- Enabled but inactive accounts.
- Misconfigured user accounts.
This is where access is defined, where attacks often begin, and where most data-centric strategies never start.
Step 2. See what your identities can access
Now that you have a general picture of what your identity risk surface is, you can start to build a picture of what data those people can really access. This is the bridge between identity and data – and where real risk starts to come to the surface:
- Which users have access to what data.
- Over-permissioned access.
- Data exposed through open shares.
- Stale data.
Together with step 1, we now have a much clearer understanding of our full risk surface, and where identity turns into exposure.
Step 3. Prioritize data risk with context
Now we need context. We need to understand what the data is, where it is, and how sensitive it is.
This is where most data-centric strategies start. But starting here ignores how breaches happen. This step should help you prioritize your risk reduction by focusing on the data that matters the most. It includes:
- Data discovery and classification.
- Tagging and categorization for sensitive data.
- Prioritization of risk based on data sensitivity and exposure.
Step 4. Observe user behavior
Now that the identity and data risk surface is fully understood, and we have prioritized where we should be focusing, we can look at user behavior:
- How users are accessing and using data.
- Changes to files, objects, and permissions.
- Unusual of risky behavior patterns.
- High-risk activity across systems (including AI tools like Copilot).
Once you build a picture of how your identities and data are interacting with one another you are ready to start actively reducing risk.
Step 5. Take action to reduce risk.
In this step, everything comes together:
- Automatically remediate excessive access.
- Detect threats and changes in behavior in real time.
- Automatically respond to threats through workflows.
- Reduce risk over time with AI-assisted notifications and suggestions.
Conclusion
Using these five steps (all of which you are able to implement with Lepide), you can take control and reduce risk at scale – in an ongoing, repeatable way.
Lepide is the only vendor in the world that truly understands the Identity-Data Disconnect. We live and breathe it. We grew up with Active Directory as our key focus, gradually incorporating data security into our unified platform over the years. Because of this, we see data security through the right lens, and we have the tools to help you make meaningful steps to reduce risk.
We’d love to show you what we do; book a demo with an expert today.
