


Unstructured sensitive data is everywhere, and it is growing at an ever-increasing rate. As organizations move to hybrid work, cloud migrations, and the use of collaboration platforms, sensitive data is being created, copied, shared, and eventually forgotten in a vast and complicated digital environment.
Manual discovery at this scale is completely out of the question, even operationally. When millions of files are distributed on-premises file servers, NAS devices, Microsoft 365, and cloud storage platforms like AWS S3 or SharePoint, the teams are simply not big enough to manually search through them all. The only viable path forward is a well-organized, automated, and constantly operating discovery process that can scale across the organization.
What is Unstructured Sensitive Data?
Unstructured data refers to information that lacks a defined or searchable database schema. It is quite different from the rows in a SQL table because it is stored in formats such as PDFs, spreadsheets, emails, images, presentations, audio files, and other documents that cannot be efficiently analyzed or classified without specialized indexing, search, or content analysis tools.
Common repositories where this data resides include:
- File Servers and NAS Storage: Old repositories that are still used to store files accumulated over many years.
- SharePoint and OneDrive: Microsoft 365 collaboration tools where documents are shared across a wide audience.
- Microsoft Teams: People use channels and chats tor shae sensitive files in a more informal way.
- Email Attachments: Various types of documents are sent back and forth in the form of email attachments.
- Cloud File Storage: Platforms such as AWS S3, Google Drive, Dropbox, and Azure Blob Storage where users store and share files.
Sensitive Data Discovery Is Only Half the Battle
Discovering sensitive files tells organizations what data exists, but not how exposed that data is.
The real risk comes from access and user behavior. It is essential for organizations to connect identity, permissions, and data visibility.
Permissions are the missing bridge in the identity-data relationship. Without understanding who the access holders are, why they have the access, and how the access is being used, sensitive data discovery efforts will, at best, be incomplete.
Categories of sensitive data that require discovery
| Data Type | Description |
|---|---|
| PII | Personally Identifiable Information, such as names, email addresses, national ID numbers, passport numbers, and biometric identifiers. |
| PHI | Protected Health Information, such as patient identifiers, diagnosis codes, treatment records, insurance information |
| PCI DSS Cardholder Data | Cardholder information such as PANs and, where stored, sensitive authentication data, including CVVs and magnetic stripe data. |
| Financial Data | Bank account numbers, SWIFT codes, tax identifiers, employment and earnings records |
| Intellectual Property | Source code, product schematics, research and development documentation, and proprietary algorithms |
| Legal Documents | Contractual agreements, NDAs, litigation holds, and regulatory correspondence. |
How Organizations Discover Unstructured Sensitive Data at Scale
Discovering sensitive data across large environments requires a systematic approach that combines visibility, automation, classification, and continuous monitoring.
1. Identify All Data Repositories
The initial phase of extensive data discovery is determining where data is located. Enterprises develop a comprehensive inventory of data storage systems spread across:
- On-premises environments
- Cloud Storage Platforms and SaaS Applications
- Hybrid Infrastructures
- Collaboration applications
This includes identifying File servers, cloud storage platforms, collaboration applications where user information is stored.
Lack of full visibility means that organizations cannot determine which data requires protection. The process of data discovery starts with the development of an understanding of where sensitive data could be present.
2. Scan Files and Content Across Repositories
Once the repositories have been identified, organizations scan files and content to locate sensitive information.
Conducting manual searches is not a reliable approach since an enterprise’s environment may contain millions of files that are scattered across thousands of folders.
Automated discovery tools help by:
- Scanning large volumes of files
- Searching file contents, metadata, and embedded document properties
- Identifying sensitive data patterns
- Running scheduled discovery scans
- Performing continuous monitoring
Periodic scanning also ensures that newly created or modified files are reviewed.
3. Detecting Sensitive Data Using Content Analysis
To find sensitive data, looking at file names is not enough. Today’s discovery systems examine file contents through several detection methods.
- Additional Detection Techniques: Locating files that contain terms such as “Confidential,” “Employee Record,” “Patient Information,” or “Financial Report.”
- Pattern Matching: Detecting structured data types such as Social Security numbers, credit card numbers, passport numbers, and tax identifiers.
- Regular Expressions Based on Patterns: Identifying data that matches predefined formats and patterns.
- Dictionary-Based Searches: After discovering sensitive information, organizations classify data based on importance and risk.
All these methods help organizations to discover hidden sensitive files even when the file name provides no indication of the content.
4. Use Data Classification to Categorize Sensitive Content
Once organizations have identified sensitive data, they usually divide it into different categories based on its level of importance and risk. Classification enables organizations to assign sensitivity labels such as Public, Internal, Confidential, and Restricted based on business and regulatory requirements. Organizations may also classify information according to regulatory requirements, including GDPR-related data, HIPAA-related information, and PCI-related data.
5. Correlate Sensitive Data with Access and Exposure Risk
Discovering sensitive data is only the first step. Additionally, organizations must know who has access to that data and how exposed it is. To find high-risk files and folders, modern data discovery software combines content analysis with access and permission data. Organizations can prioritize the most important risks and concentrate remediation efforts where they will have the greatest impact by linking sensitive data finds with permissions, group memberships, external sharing settings, and user activity.
6. Analyze Permissions and Access Rights
Finding sensitive data is only part of the process. It’s equally crucial for companies to know who can access that data. Permission analysis identifies users, groups, and external parties with access to sensitive files, users with excessive permissions, overexposed folders, and files accessible to large groups. Analyzing access rights helps organizations enforce least-privilege access and reduce exposure.
7. Use AI and Machine Learning to Improve Discovery Accuracy
Traditional discovery techniques may produce false positives because they often rely primarNewily on pattern matching and keyword detection. Using AI and machine learning, detection accuracy can be improved by analyzing document context, semantic meaning, content relationships, and behavioral patterns. Besides, discovery fueled by AI can detect sensitive documents even when they lack the exact keywords.
8. Prioritize High-Risk Data for Remediation
Not all sensitive data is equal risk- wise. Factors that help prioritize remediation are:
- Old sensitive data no longer required.
- Sensitive files accessible by too many users.
- Data stored in unsecured locations.
- Files shared externally through collaboration platforms, email, or public links.
- Sensitive data stored in collaboration platforms without proper controls.
Prioritization makes sure that the most risky exposures are dealt with first rather than teams spending time on low-risk findings.
9. Continuously Monitor for new Sensitive Data
Data environments are constantly changing. Employees create new documents, modify existing files, and share information on a regular basis. Continuous monitoring allows organizations to identify newly created sensitive files, where data has been moved, what rules have been broken, and maintain visibility over time. Continuous discovery makes sure that the protection of sensitive data is a regularly occurring function and not a single activity.
Why Unstructured Data Discovery Is Essential for Compliance and Data Governance
The reasons unstructured data discovery is essential for compliance and data governance are listed below:
- Meeting Regulatory Requirements: Organizations are expected to know where sensitive data is and how it is being protected. Data discovery is a big part of complying with regulations and frameworks such as GDPR, HIPAA, PCI DSS, SOX, and other applicable regulatory frameworks. To prove that they are complying with regulations, organizations must know where sensitive data is, who has access to it, and what security measures are in place.
- Support Data Minimization Efforts: One of the easiest and most effective means of risk reduction is not to keep unnecessary sensitive information. Discovery helps organizations recognize the ROT (Redundant, Obsolete, and Trivial) data, sometimes referred to as redundant or stale data like duplicate files, expired contracts, and archival records which no longer have a business purpose and remove them through deletion or archiving. So, by removing excessive sensitive data not only eliminate security risks but also help organizations save on data storage costs.
- Enabling Access Reviews: Developing a deep knowledge of who can get to the sensitive files is essential when it comes to enforcing the least privilege principle. Discovery-based access reviews identify files that are overly exposed and allows the security team to reduce the permission level, eliminate old access rights, and verify that only those with the necessary authorization can get to the sensitive content.
- Improving Audit Readiness: The key point of compliance audits is providing evidence, not just writing down policies. Discovery platforms help produce detailed records to demonstrate that sensitive data was located, classified, protected through appropriate controls, and access was controlled. Such audit trails reduce the stress of regulatory audits and show a forward-looking, control-based approach to data governance.
- Reducing Data Exposure Risks: Sensitive data stored in inappropriate locations like personal drives, unsecured cloud storage containers (such as S3 buckets), or publicly accessible SharePoint sites is exposing risk. Discovery tool finds these risks before attackers or regulators, thereby giving organizations an opportunity to remediate the issue first.
How Lepide Helps Organizations Discover Unstructured Sensitive Data at Scale
Lepide Identify helps organizations discover and classify sensitive data within unstructured data repositories based on content, risk and value. Lepide classifies files the moment they are created and tags them. This adds context to data-related reports so security teams can filter and focus on the data that matters most. Here’s how it works:
- Scans Unstructured Data Sources: Lepide scans file servers and cloud data stores to locate sensitive data across large data environments. For instance, let’s focus on Windows File Server, one of the most common locations for unstructured data. Navigate to the File Server reports within Lepide Identify to begin analyzing stored files.
- Generate Classified Files Report: Lepide automatically classifies files and applies tags that identify the type of sensitive data they contain. This helps compliance teams quickly understand the nature of the data stored within each file. For this, open the Classified Files Report to view files that have been analyzed and categorized based on their content.
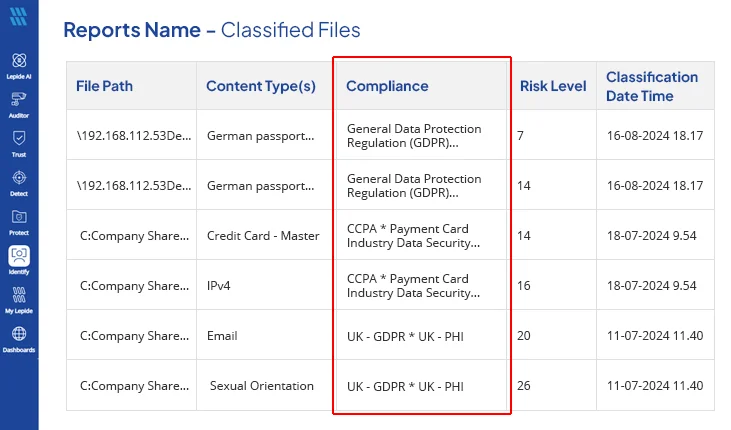
- Review Sensitive Data Classification Results: Once the report is generated, it categorizes sensitive files and shows where sensitive data resides, helping teams understand data exposure risks.
- Access Risk and Compliance Exposure: For every file, Lepide shares additional information like the type of sensitive data detected, associated risk level, applicable compliance regulations, the number of sensitive data instances identified, and estimated business value of the data which helps organizations prioritize remediation efforts and focus on high risk data.
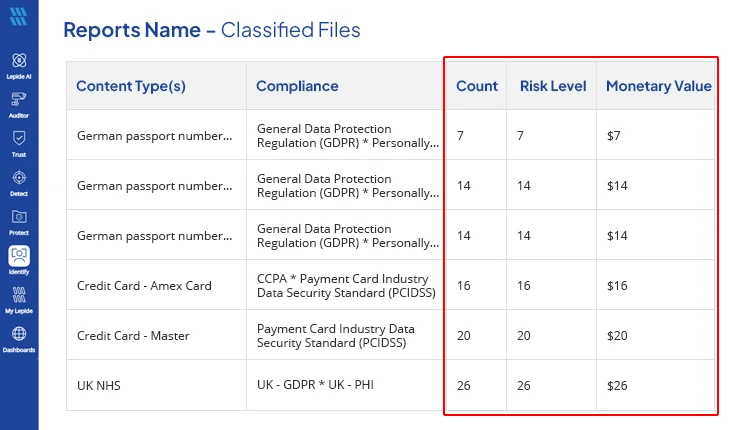
- Prioritize High-Risk Data: By highlighting high-risk sensitive data, Lepide helps security teams focus remediation efforts on critical information first.
Discover how Lepide helps automate data discovery, classification and risk assessment to identify sensitive unstructured data at scale, strengthen security and controls, and simplify compliance. Schedule a demo with one of our engineers today to see how it works in action.
Frequently Asked Questions
Unstructured sensitive data refers to information that is saved in formats like documents, emails, PDFs, images, and other files that contain personal identifying information (PII), personal health information (PHI), financial records, intellectual property, legal documents, etc.
Usually, sensitive unstructured data is stored in file servers, NAS devices, SharePoint, OneDrive, Microsoft Teams, email attachments, and cloud storage spaces.
Automated scanning, content analysis, regular expressions, pattern recognition, data classification, AI, machine learning, and permission checking are among the technologies that businesses use to discover unstructured data.
Since sensitive data is constantly being created, changed, and shared among different business environments, companies should perform continuous or, at minimum, scheduled scanning.